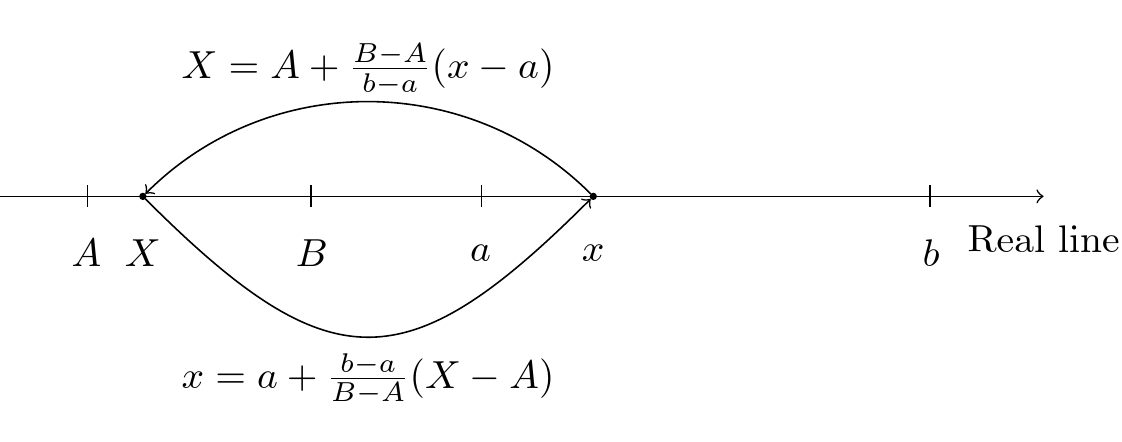\(\{\hat{u}_k\}_{k=0}^N\) are expansion coefficients (the unknowns)
\(V_N = \text{span}\{\psi_k\}_{k=0}^N\) is a function space (which is a vector space)
For example, \(V_N = \text{span}\{x^k\}_{k=0}^N\) is the space of all polynomials of order less than or equal to \(N\). (More commonly referred to as \(\mathbb{P}_N\))
If we say that \(u_N \in V_N\), then we mean that \(u_N\) can be written as \((1)\) and that \(u_N\) is a vector in the vector space (or function space) \(V_N\).
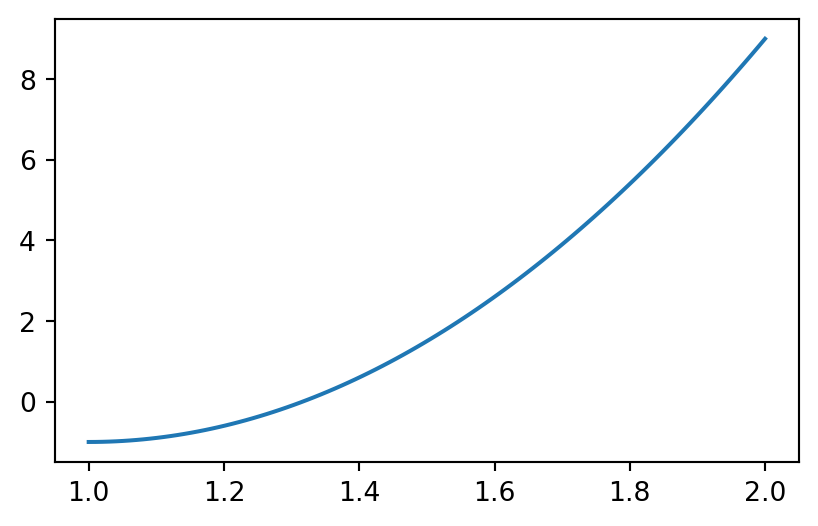
Example: \(u(x) = 10(x-1)^2-1\) for \(x\in [1,2]\)
Let \(V_N = \text{span}\{1, x\}\) be the space of all straight lines.
What is the best approximation \(u_N \in V_N\) to the function \(u(x)\)?
How do we decide what is best? All we know is that
\[
u_N(x) = \hat{u}_0 + \hat{u}_1 x.
\]
How to find the best\(\{\hat{u}_0, \hat{u}_1\}\)?
How to find the best approximation?
What options are there? Who decides what is best?
The three methods covered in this class are
The least squares method
The Galerkin method
The collocation method
The first two are variational methods, whereas the third is an interpolation method.
Each method will give us \(N+1\) equations for the \(N+1\) unknowns \(\{\hat{u}_k\}_{k=0}^N\)!
A variational method derives equations by using integration over the domain
A collocation method derives equations at different points in the mesh
Variational methods
Since a variational method derives equations by integrating over the domain, we need to define a special notation. The \(L^2\) inner product is defined as
\[
\left(f, g \right) = \int_{\Omega} f(x)g(x) d\Omega,
\]
for two real functions \(f(x)\) and \(g(x)\) (complex functions have a slightly different inner product). The symbol \(\Omega\) here represents the domain of interest. For our first example \(\Omega = [1, 2]\).
Note
Sometimes the inner product is written as \(\left(f, g \right)_{L^2(\Omega)}\), in order to clarify that it is the \(L^2\) inner product on a certain domain. Normally, the \(L^2(\Omega)\) subscript will be dropped.
The \(\small L^2(\Omega)\) norm
The inner product is used to define an \(L^2(\Omega)\)norm
\[
\|u\| = \sqrt{(u, u)}
\]
The norm gives us a measure for the length or size of a vector.
where \(\|\psi_i\|^2\) is the squared \(L^2\) norm of \(\psi_i\). We can still easily solve the linear algebra system (because \(A\) is a diagonal matrix)
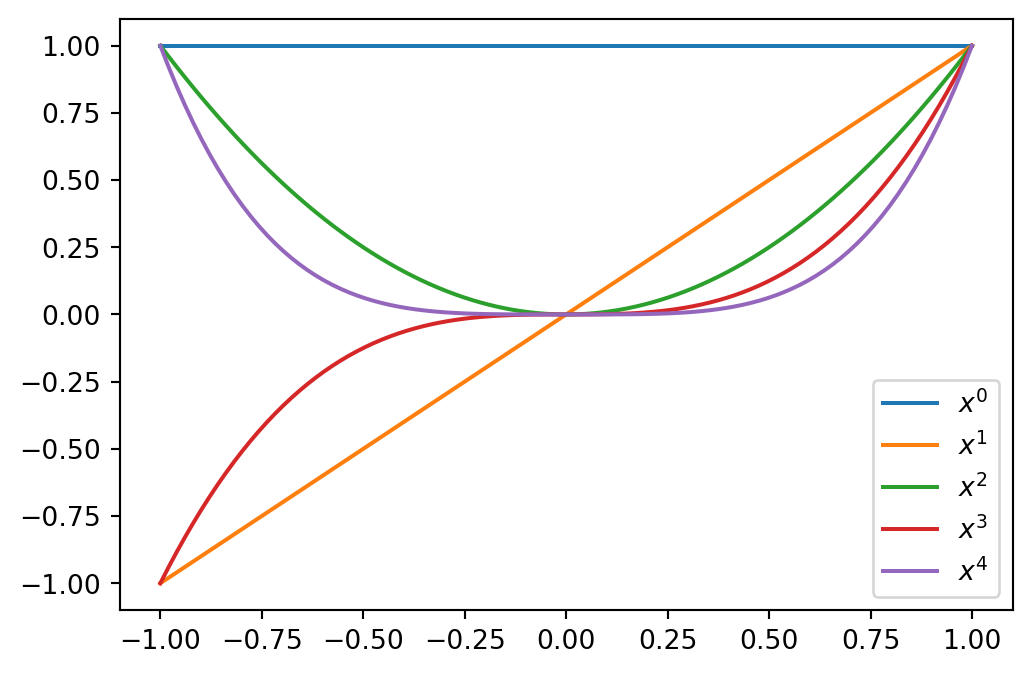
is a basis for \(\mathbb{P}_N\). However, it is not a good basis. This is because the basis functions are not orthogonal and the mass matrix \(A\) is ill conditioned. In short, this means it is difficult to solve \(A\boldsymbol{x}=\boldsymbol{b}\) with good accuracy using finite precision computers.
The basis functions are shown below for \(x\in [-1, 1]\)
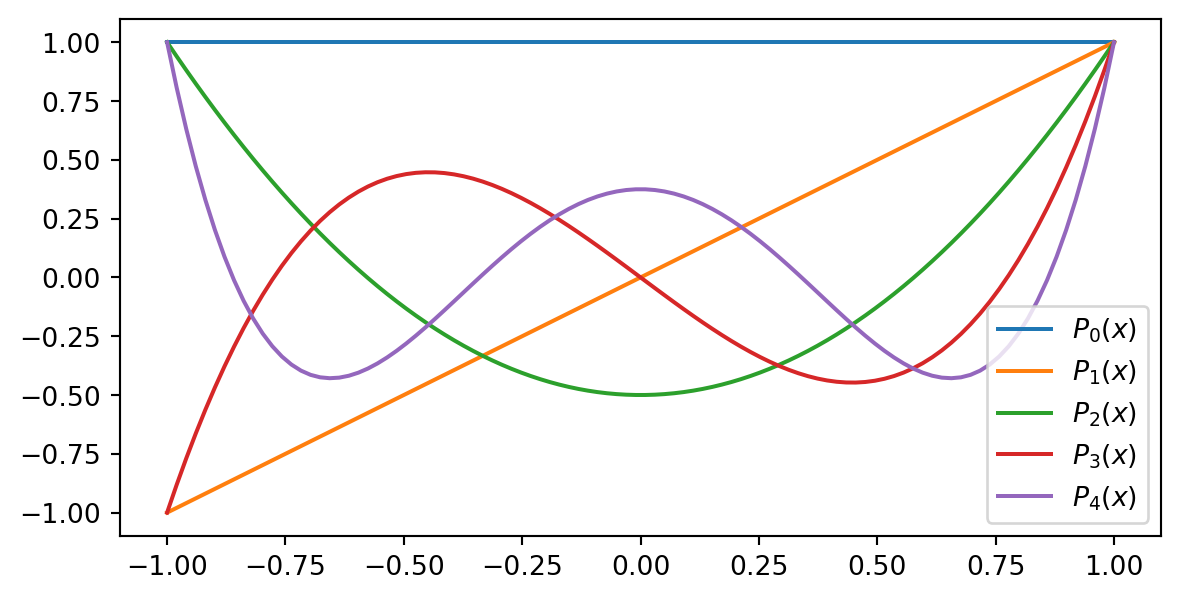
Legendre polynomials are much better basis functions
Legendre polynomials, \(P_i(x)\), are defined on the domain \(\Omega = [-1, 1]\) as the recursion
This requires that the domain of \(u(x)\) is \([-1, 1]\)
If the physical domain \([a, b]\) is different from the reference domain \([-1, 1]\), then we need to map
Many well-known basis functions work only on a given reference domain
Sines and cosines \([0, \pi]\)
Legendre polynomials \([-1, 1]\)
Bernstein polynomials \([0, 1]\)
Chebyshev polynomials \([-1, 1]\)
Let \(X\) be the coordinate in the computational (reference) domain \([A, B]\) and \(x\) be the coordinate in the true physical domain \([a, b]\). A linear (affine) mapping, from \(X\) to \(x\) (and back) is then
\[
X \in [A, B] \quad \text{and} \quad x \in [a, b]
\]
\[
x = a + \frac{b-a}{B-A}(X-A) \quad \text{and} \quad X = A + \frac{B-A}{b-a}(x-a)
\]
Affine map
Equations are defined in the real domain \([a, b]\)
Equations are solved in the computational domain \([A, B]\)
The mapping makes it possible to use Legendre polynomials in any domain \([a, b]\)
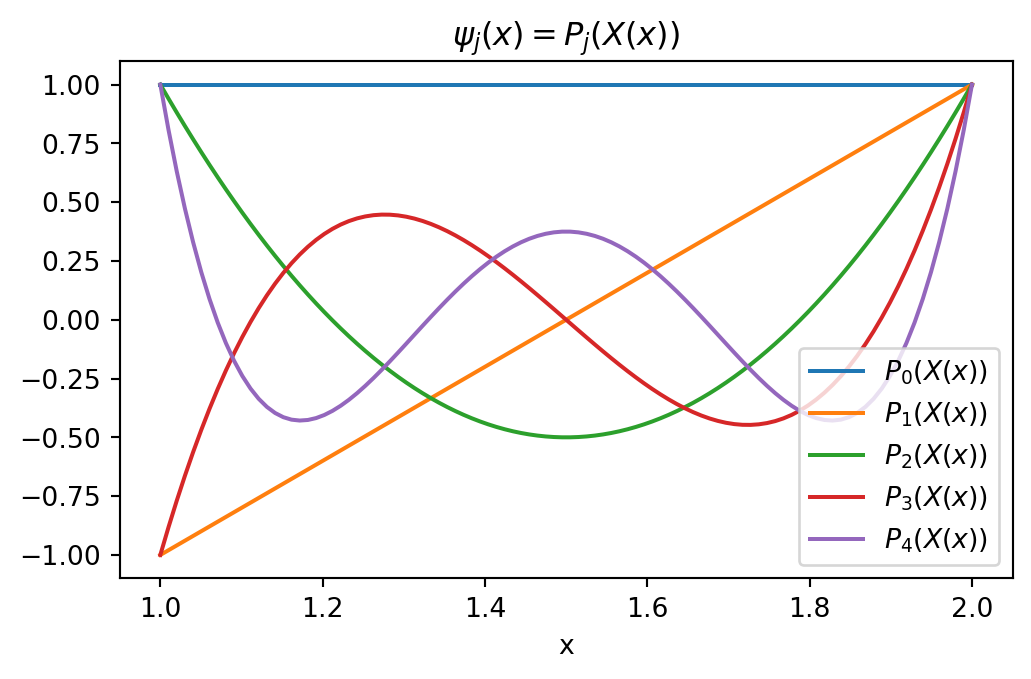
The basis functions \(\psi_j(x)\) are simply
\[
\psi_j(x) = P_j(X(x)) \quad X \in [-1, 1], \quad x \in [a, b]
\]
\[
X(x) = -1 + \frac{2}{b-a}(x-a)
\]
xj = np.linspace(1, 2, 100)A, B =-1, 1a, b =1, 2Xj =-1+ (B-A)/(b-a)*(xj-a)plt.figure(figsize=(6, 3.5))legend = []p = np.zeros(100)for n inrange(5): l = sp.legendre(n, x) p[:] = sp.lambdify(x, l)(Xj) plt.plot(xj, p) legend.append(f'$P_{n}(X(x))$')plt.title(r'$\psi_j(x)=P_j(X(x))$')plt.xlabel('x')plt.legend(legend);
The mapping complicates the inner product
The Galerkin method is defined on the true domain using \(L^2([a, b])\)
Now introduce \(\psi_j(x) = P_j(X(x))\) and \(\psi_k(x) = P_k(X(x))\) and integrate with a change of variables \(x\rightarrow X\). The new integration limits are then \(X(a)=-1\) and \(X(b)=1\)
The following inner product is valid for any mapping
def inner(u, v, domain, ref_domain=(-1, 1)): A, B = ref_domain a, b = domain X = a + (b-a)*(x-A)/(B-A) us = u.subs(x, X) # u(x(X))return sp.integrate(us*v, (x, A, B))
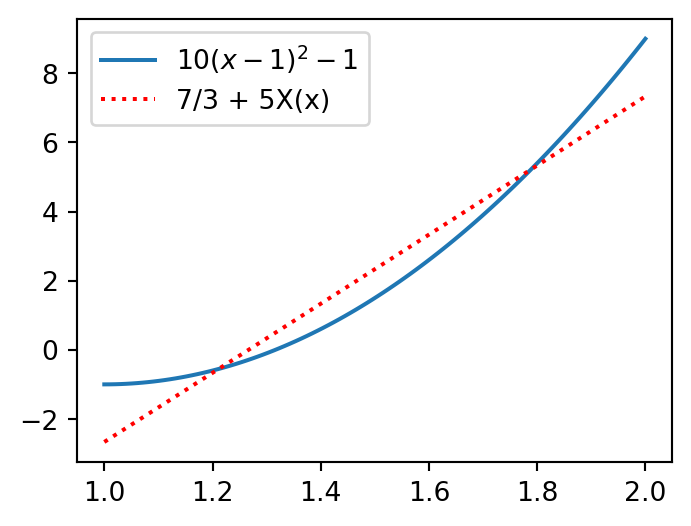
For example, for our \(u(x)=10(x-1)^2-1\) in the domain \(\Omega = [a, b] = [1, 2]\) we get
The Legendre polynomials use the reference coordinate \(X\), whereas the true function \(u_N(x)\) is a function of \(x\) from the true space.
Note
The inner product implemented here is using Sympy’s integrate function, which may be too slow or not find the solution at all. It is normally better to use scipy.integrate.quad
There is no integration and the method is often favored for its simplicity. There is a problem though. How do you choose the collocation points?!
Note
The Lagrange polynomial here is using all \(N+1\) mesh points. This is different from lecture 7, where we only used a few mesh points close to the interpolation point.
Lagrange collocation method for \(u(x)=10(x-1)^2-1, x\in[1,2]\)
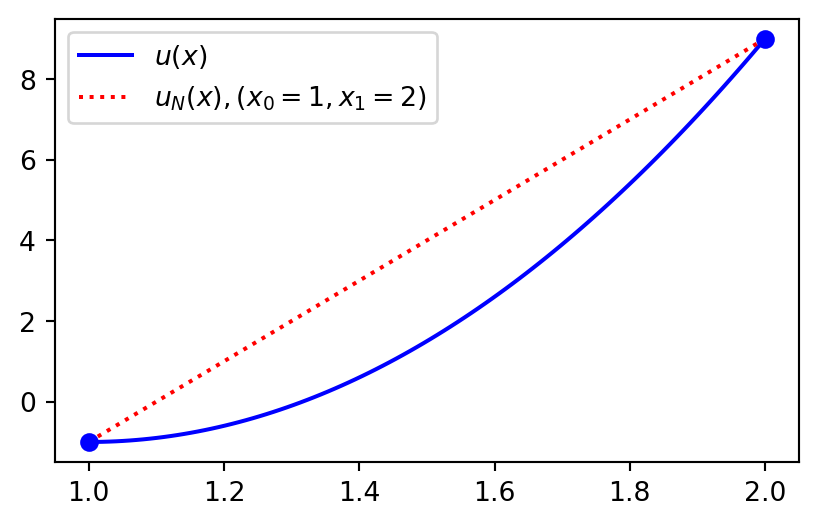
The approximation using two collocation points (linear function, \(u_N \in V_N=\text{span}\{1, x\}\)) is
We can choose the end points \(x_0=1\) and \(x_1=2\) and reuse the two functions Lagrangebasis and Lagrangefunction from lecture 7. The result is then as shown on the next slide
Collocation
from lagrange import Lagrangebasis, Lagrangefunctionxj = np.linspace(1, 2, 100)u =10*(x-1)**2-1xp = np.array([1, 2])ell = Lagrangebasis(xp)L = Lagrangefunction([u.subs(x, xi) for xi in xp], ell)plt.figure(figsize=(5, 3))plt.plot(xj, sp.lambdify(x, u)(xj), 'b')plt.plot(xj, sp.lambdify(x, L)(xj), 'r:')plt.plot(xp, [u.subs(x, xi) for xi in xp], 'bo')plt.legend(['$u(x)$', '$u_N(x), (x_0=1, x_1=2)$']);
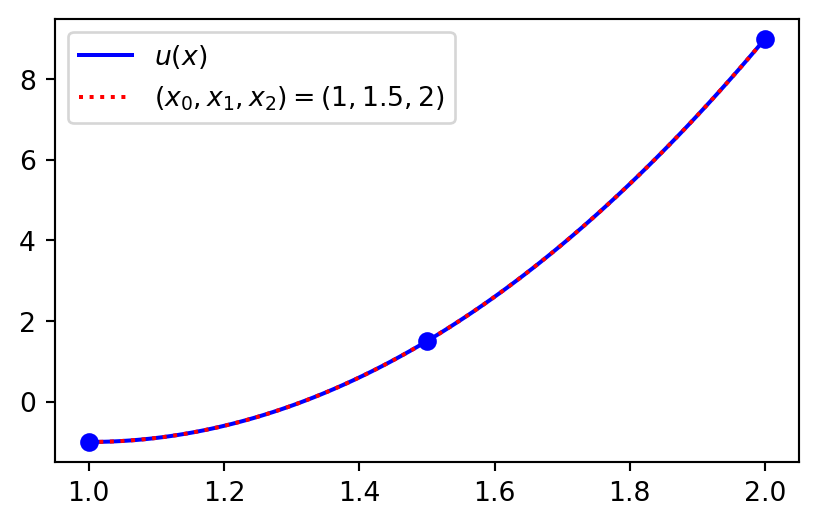
Use three points and the approximation is perfect because \(u(x)\) is a 2nd order polynomial
xp = np.array([1, 1.5, 2])ell = Lagrangebasis(xp)L = Lagrangefunction([u.subs(x, xi) for xi in xp], ell)plt.figure(figsize=(5, 3))plt.plot(xj, sp.lambdify(x, u)(xj), 'b')plt.plot(xj, sp.lambdify(x, L)(xj), 'r:')plt.plot(xp, [u.subs(x, xi) for xi in xp], 'bo')plt.legend(['$u(x)$', '$(x_0, x_1, x_2) = (1, 1.5, 2)$']);
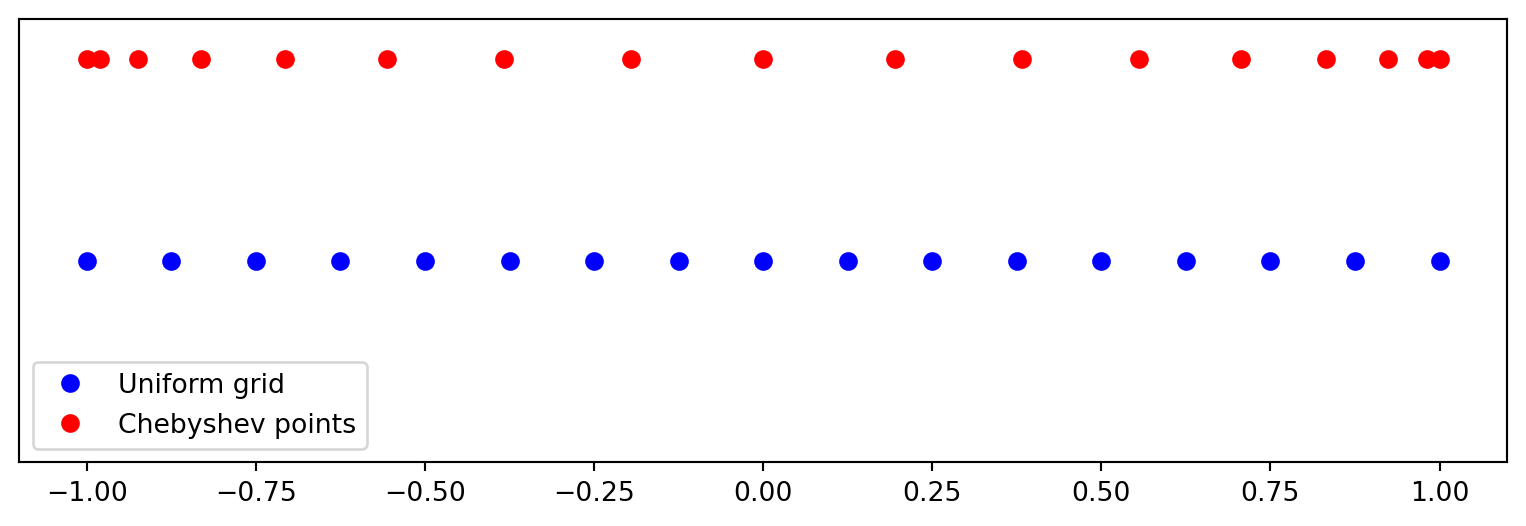
High order interpolation on uniform grids is bad
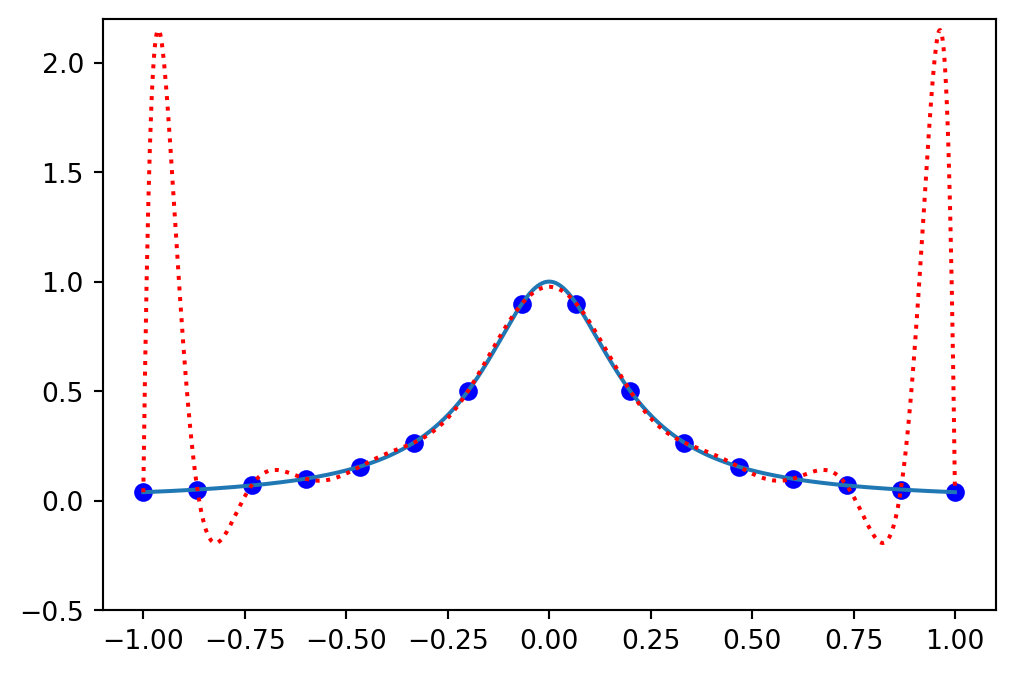
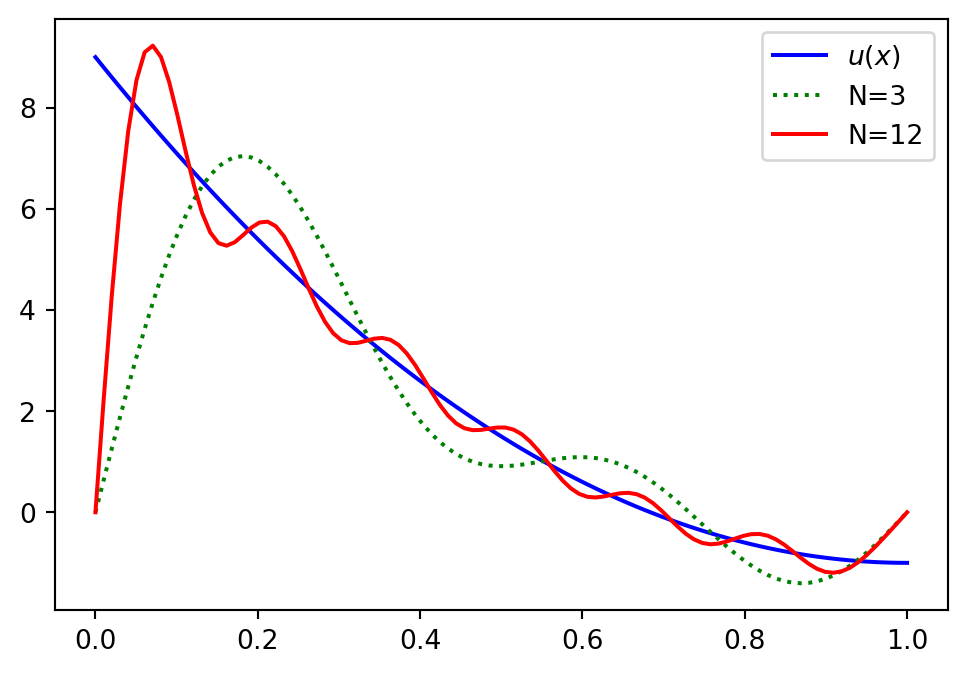
Lets consider a more difficult function
\[
u(x) = \frac{1}{1+25x^2}, \quad x \in [-1, 1],
\]
and attempt to approximate it with Lagrange polynomials on a uniform grid.
Use
\[\begin{align}
N &= 15 \\
x_i &= -1 + \frac{2i}{N}, \quad i=0, 1, \ldots, N \\
u(x_i) &= u_N(x_i) = \sum_{j=0}^N u(x_j) \ell_j(x_i), \quad i=0, 1, \ldots, N
\end{align}\]
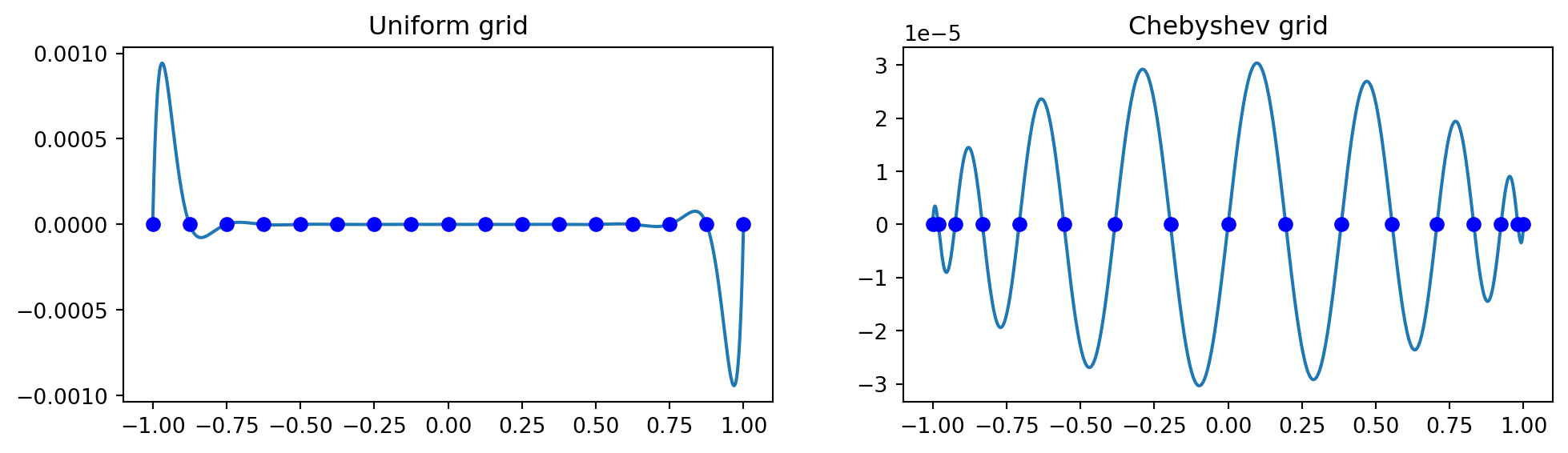
Only small oscillations - interpolation is converging using more points!
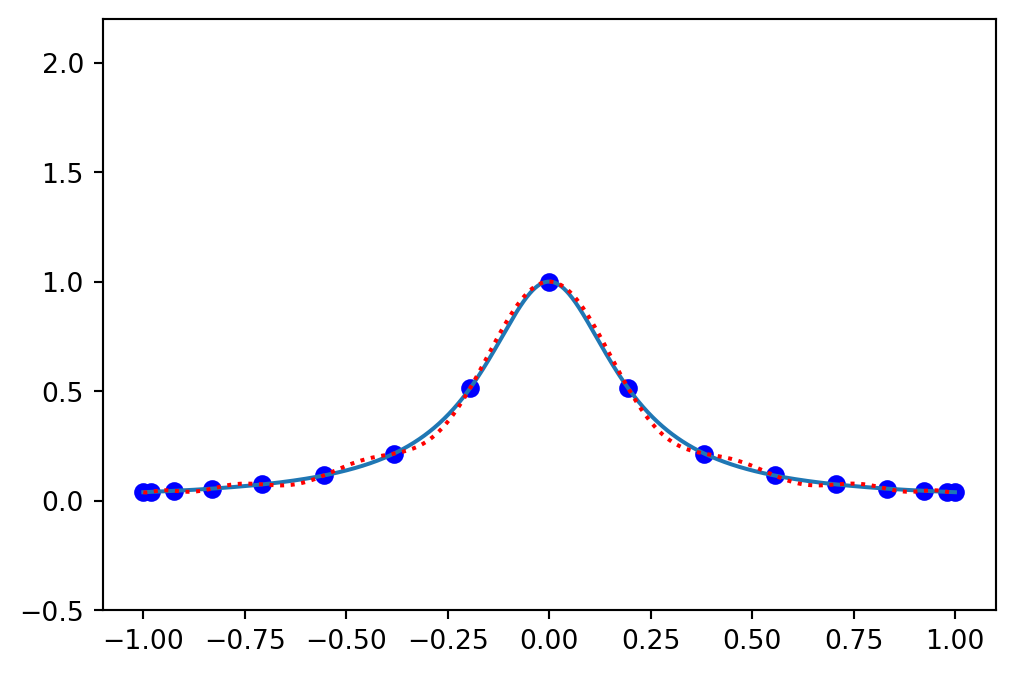
The variational method and \(\small u(x)=\frac{1}{1+25x^2}\)
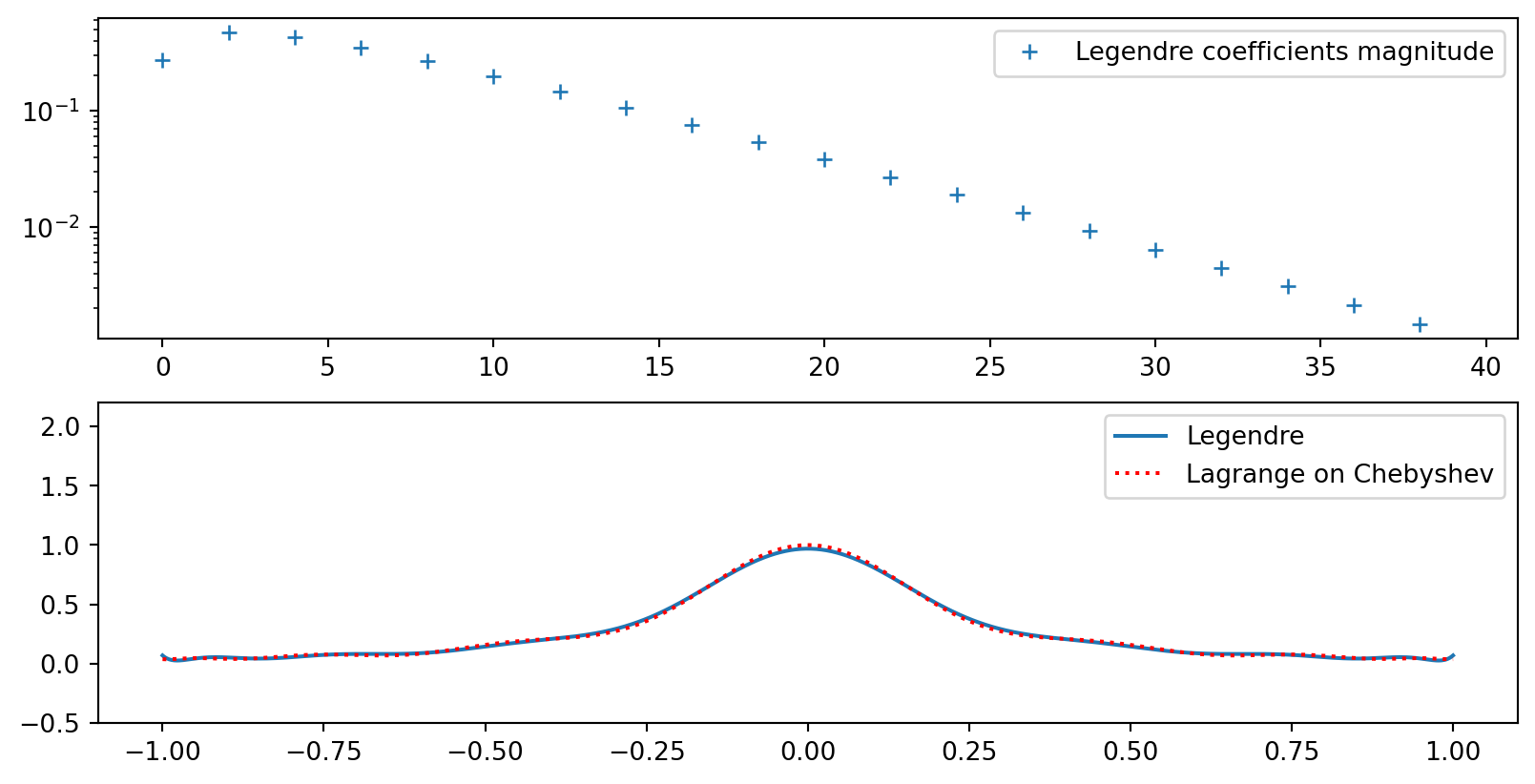
Lets try Legendre polynomials. There is no need for mapping since the domain is \([-1, 1]\). And there are no mesh points! The Legendre coefficients are
# Use scipy to compute integralfrom numpy.polynomial import Legendrefrom scipy.integrate import quaddef innern(u, v): uj =lambda xj: sp.lambdify(x, u)(xj)*v(xj)return quad(uj, -1, 1)[0]u =1/(1+25*x**2)uhat =lambda u, j: (2*j+1) * innern(u, Legendre.basis(j))/2ul = [uhat(u, n) for n inrange(40)]xj = np.linspace(-1, 1, 1000)uj = sp.lambdify(x, u)(xj)fig, (ax1, ax2) = plt.subplots(2, 1)ax1.semilogy(abs(np.array(ul)), '+')ax2.plot(xj, Legendre(ul[:17])(xj))ax2.plot(yj, sp.lambdify(x, L)(yj), 'r:')ax2.set_ylim(-0.5, 2.2);ax1.legend(['Legendre coefficients magnitude'])ax2.legend(['Legendre', 'Lagrange on Chebyshev'])
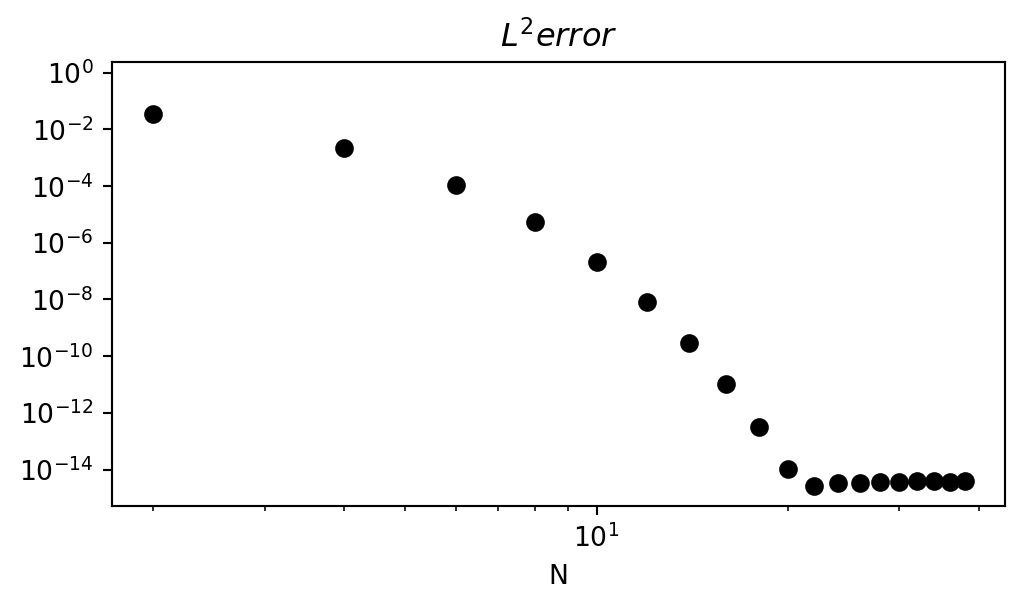
Error in Legendre approximations
The smooth function \(u(x)\) can be exactly represented as
\[
u(x) = \sum_{k=0}^{\infty} \hat{u}_k P_k(x)
\]
For all \(k \le N\) the series for \(u(x)\) and the series for \(u_N(x)\) have exactly the same coefficients \(\hat{u}_k\). Hence the error in the approximation \(u_N\) is easily computed as
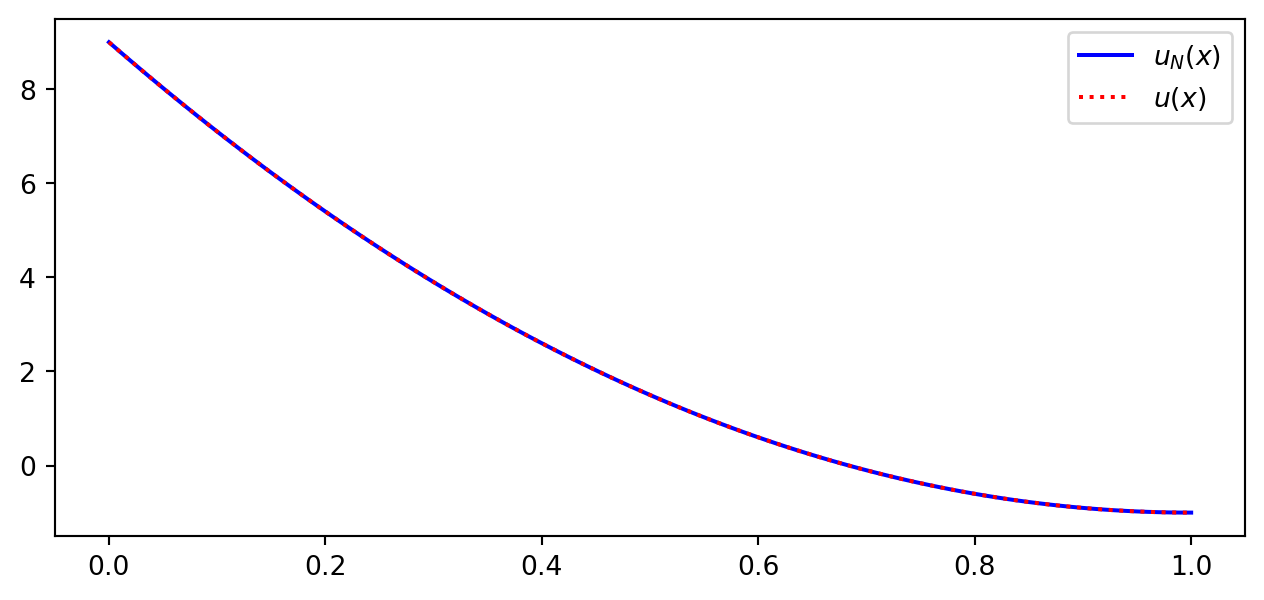
Hence there is no need for boundary functions or adjustments
uhat =lambda u, j: (2*j+1) * inner(u, sp.legendre(j, x), (0, 1))/2uL = [uhat(u, i) for i inrange(6)]plt.figure(figsize=(8, 3.5))plt.plot(xj, Legendre(uL, domain=(0, 1))(xj), 'b')plt.plot(xj, 10*(xj-1)**2-1, 'r:'); plt.legend([r'$u_N(x)$', r'$u(x)$'])print(uL)
[7/3, -5, 5/3, 0, 0, 0]
Summary
We have been approximating \(u(x)\) by \(u_N \in V_N = \text{span}\{\psi_j\}_{j=0}^N\), meaning that we have found \(\small u_N(x) = \sum_{j=0}^N \hat{u_j} \psi_j(x)\)
We have found the unknown expansion coefficients \(\{\hat{u}_j\}_{j=0}^N\) using
Variational methods
The least squares method
The Galerkin method
Collocation - an interpolation method
Interpolation on uniform grids is bad for large \(N\) due to Runge’s phenomenon
Basis functions are often defined on a reference domain, and problems thus need mapping.
Some basis functions, like sines, have zero boundary values and need an additional boundary function for convergence.
Legendre polynomials lead to spectral convergence (for smooth functions \(u(x)\)).