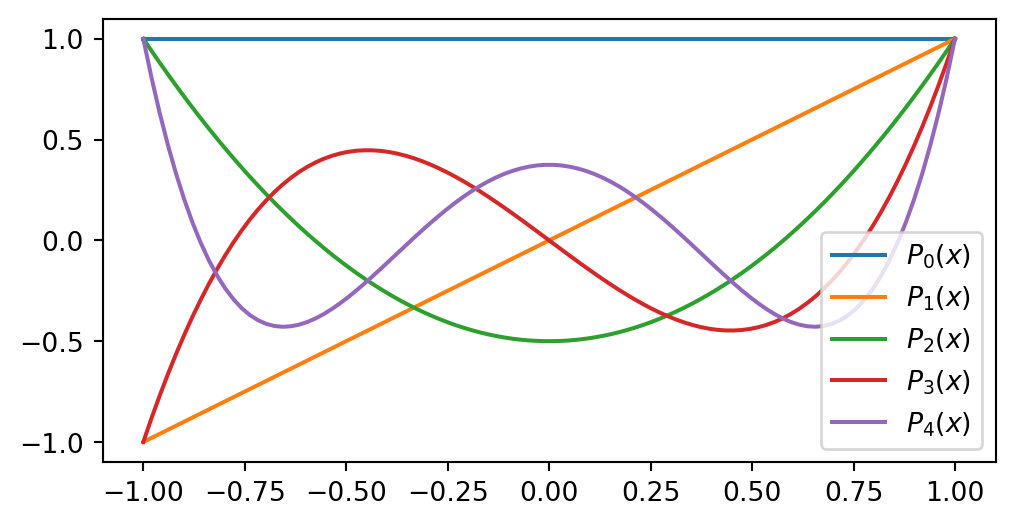
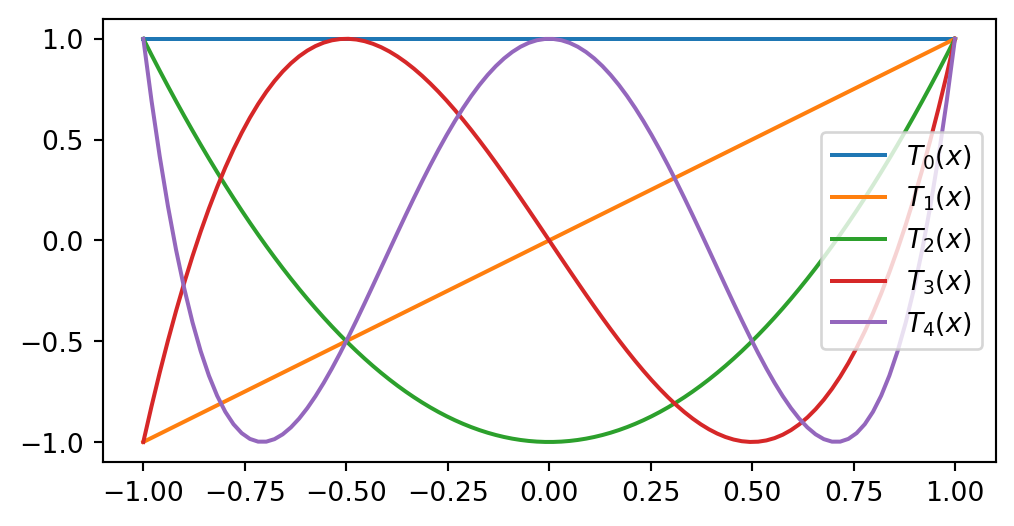
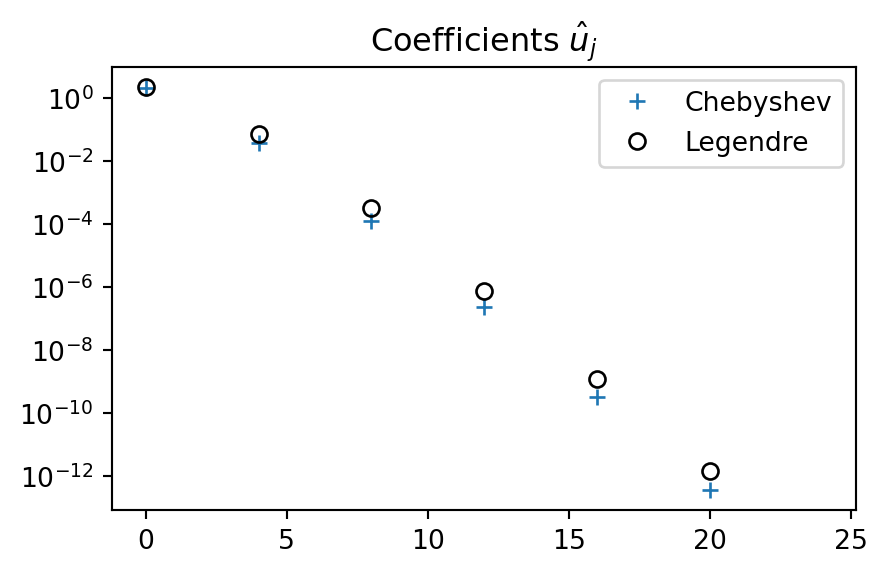
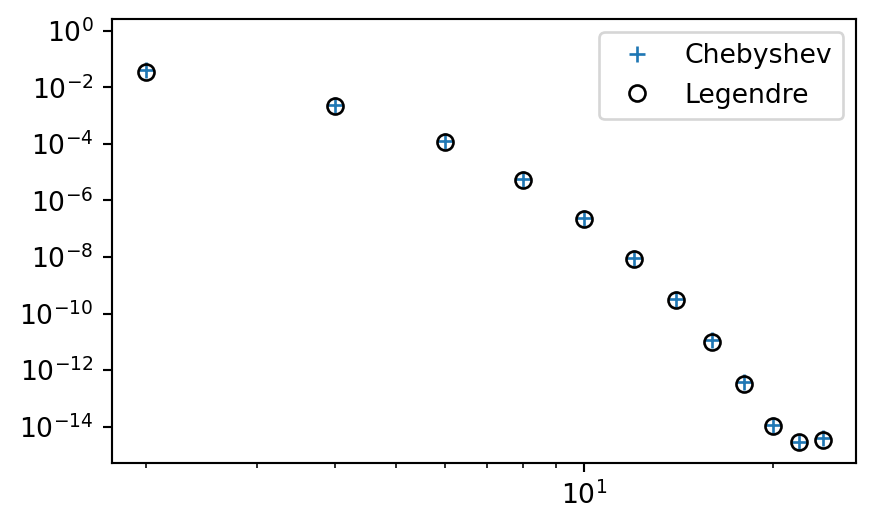
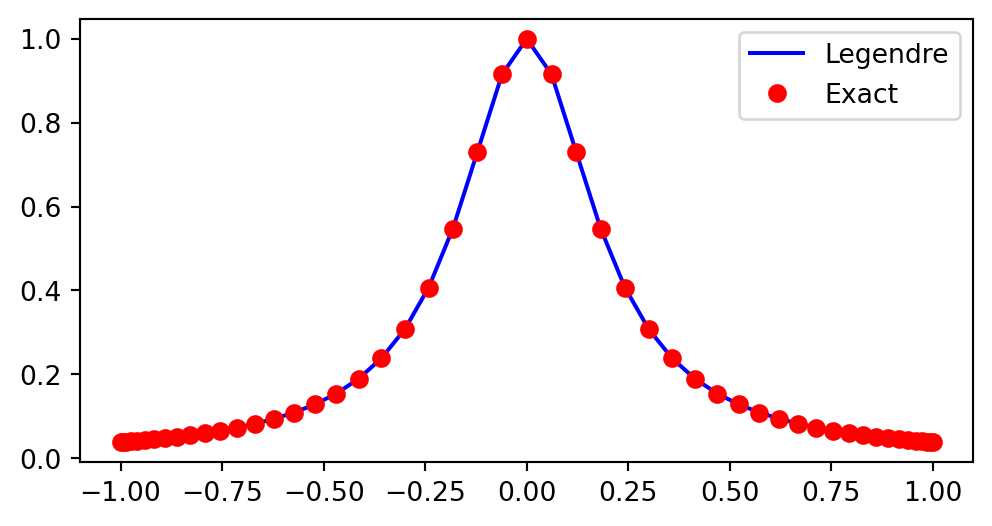
The Chebyshev polynomials \(\{T_j\}_{j=0}^N\) also form a basis for \(\mathbb{P}_N\). However, the Chebyshev polynomials are not orthogonal in the \(L^2(-1, 1)\) space!
Since \(T_i(X) = \cos(i \cos^{-1}(X))\) a change of variables \(X=\cos \theta\) leads to \(T_i(\cos \theta) = \cos(i \theta)\). Using the change of variables for the integral:
x = sp.Symbol('x', real=True)k = sp.Symbol('k', integer=True, positive=True)Tk =lambda k, x: sp.cos(k * sp.acos(x))cj =lambda j: 2if j ==0else1def innerw(u, v, domain, ref_domain=(-1, 1)): A, B = ref_domain a, b = domain# map u(x(X)) to use reference coordinate X.# Note that small x here in the end will be ref coord. us = u.subs(x, a + (b-a)*(x-A)/(B-A))# Change variables x=cos(theta) us = sp.simplify(us.subs(x, sp.cos(x)), inverse=True) # X=cos(theta) vs = sp.simplify(v.subs(x, sp.cos(x)), inverse=True) # X=cos(theta)return sp.integrate(us*vs, (x, 0, sp.pi))
Note
We use the Sympy function simplify with inverse=True, which is required for Sympy to use that \(\cos^{-1}(\cos x) = x\), which is not necessarily true.
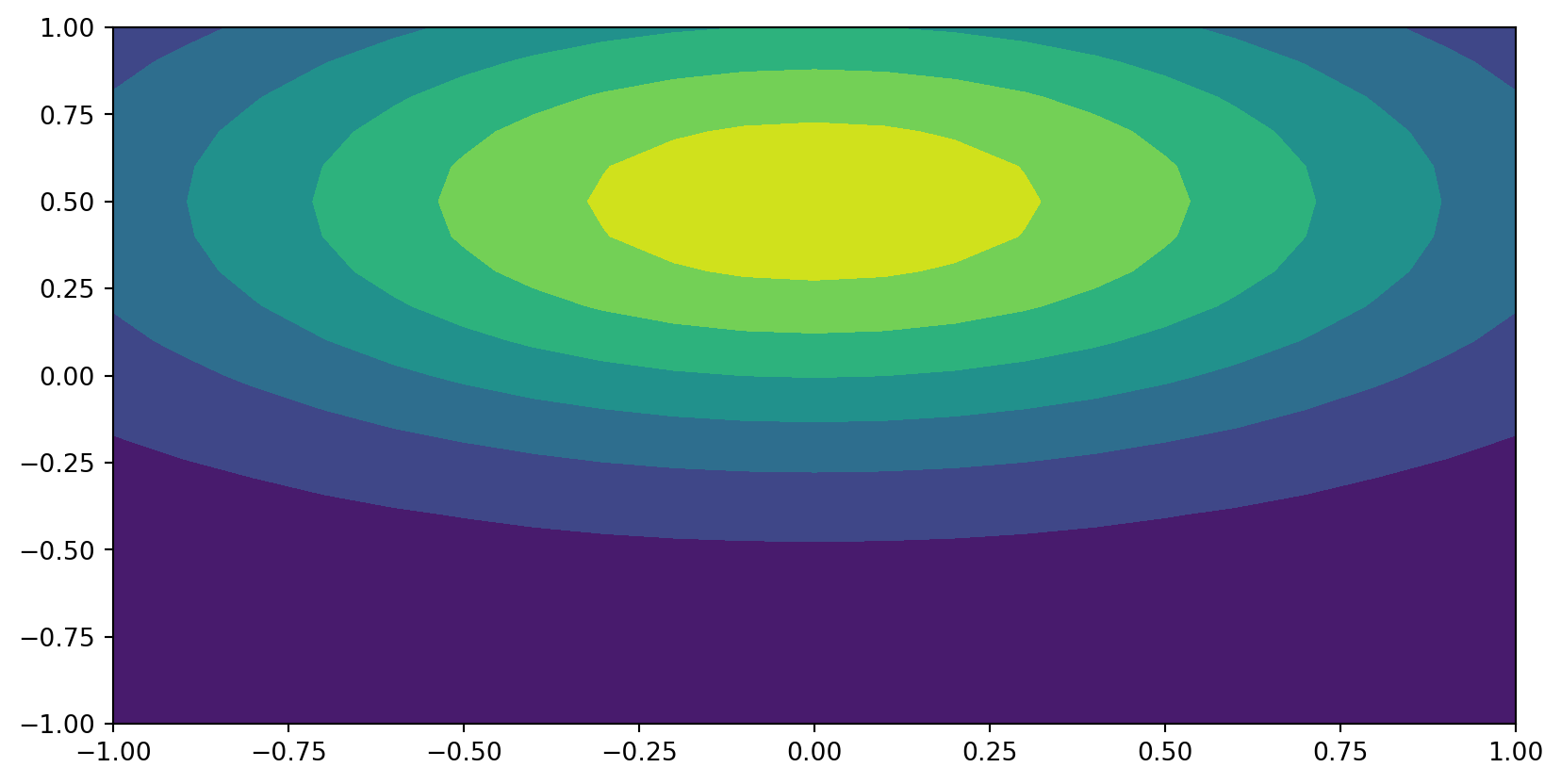
\(\Psi_{i}(x, y)\) is a two-dimensional basis function
\(\{\Psi_i\}_{i=0}^N\) is a basis
\(W_N = \text{span}\{\Psi_i\}_{i=0}^N\) is a 2D function space.
It is more common to use one basis function for each direction
There are not all that many two-dimensional basis functions and a more common approach is to use one basis function for the \(x\)-direction and another for the \(y\)-direction
We have a function space and a basis, now it’s time to approximate \(\small u(x,y)\)
The variational methods require the \(L^2(\Omega)\) inner product
\[
\begin{align*}
(f, g)_{L^2(\Omega)} &= \int_{\Omega} f g \, d\Omega, \\
&= \int_{I_x}\int_{I_y} f(x,y)g(x,y)dxdy.
\end{align*}
\]
Note
The first line is identical to the definition used for the 1D case and is valid for any domain \(\Omega\), not just Cartesian product domains. The only difference for 2D is that \(f\) and \(g\) now are functions of both \(x\) and \(y\) and the the integral over the domain is a double integral.
Galerkin for 2D approximations
We want to approximate
\[
u(x, y) \approx u_N(x, y)
\]
The Galerkin method is then: find \(u_N \in W_N\) such that
\[
(u - u_N, v) = 0, \quad \forall \, v \in W_N \tag{1}
\]
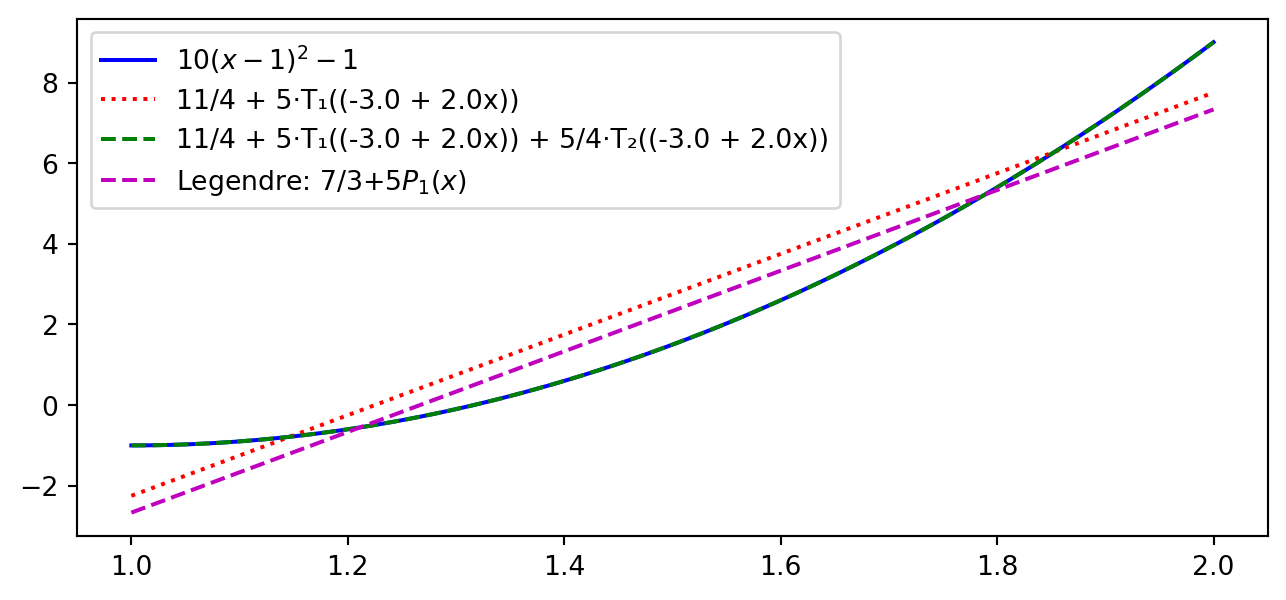
In order to solve the problem we just choose basis functions and solve (1). For example, use Legendre polynomials in both \(x\) and \(y\)-directions.
Note that the unknown coefficients \(\hat{u}_{ij}\) are independent of space and we can simplify the double integrals by separating them into one integral for \(x\) and one for \(y\). For example
\[
\begin{align}
\sum_{i=0}^{N_x} \sum_{j=0}^{N_y} a_{mi}a_{nj} \hat{u}_{ij} &= u_{mn}, \quad (m,n)\in (0, \ldots, N_x) \times (0, \ldots, N_y) \\
\longrightarrow A \hat{U} A &= U
\end{align}
\]
Can solve for \(U\) with the vec-trick (\(\text{vec}(A \hat{U} A^T) = (A \otimes A) \text{vec}{(\hat{U})}\))
\[
\begin{align}
(A \otimes A) \text{vec}(\hat{U}) &= \text{vec}(U) \\
\text{vec}(\hat{U}) &= (A \otimes A)^{-1} \text{vec}(U)
\end{align}
\]
However, since \(A\) here is a diagonal matrix and we only have one matrix \((A\hat{U}A)\) it is actually much easier to just avoid the vectorization and solve directly
for any \(x, y\), preferably within the domain \([-1, 1] \times [-1, 1]\).
How to do this?
A simple double for-loop will do, or on matrix-vector form to avoid the for-loop. Use \(\boldsymbol{P_x}=(P_0(x), \ldots, P_{N_x})\) and \(\boldsymbol{P_y}=(P_0(y), \ldots, P_{N_y}(y))\)
It is very common to compute the solution on a 2D computational Cartesian grid \(\boldsymbol{x}= (x_0, x_1, \ldots, x_{N_x})\) and \(\boldsymbol{y}=(y_0, y_1, \ldots, y_{N_y})\):
\[
\boldsymbol{x} \times \boldsymbol{y} = \{(x, y) | x \in \boldsymbol{x} \text{ and } y \in \boldsymbol{y}\}
\]
Note the implementation. Choose FunctionSpace and compute Legendre coefficients using the inner product, with \(v=P_j\) as a TestFunction for the function space V.
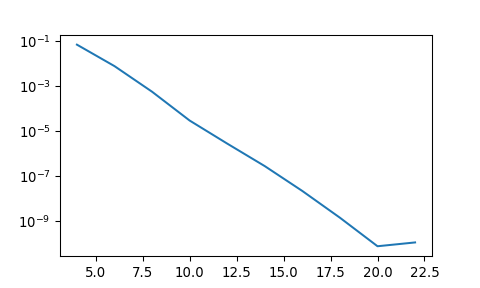
Slow because you use \(\mathcal{O}(N^2)\) floating point operations and memory demanding because you need a matrix \(\boldsymbol{T} \in \mathbb{R}^{(N+1)\times (N+1)}\).
Lets describe a faster way to compute \(\boldsymbol{u}=(u_N(x_i))_{i=0}^N\) from \(\boldsymbol{\hat{u}}=(\hat{u}_i)_{i=0}^N\)
The discrete cosine transform of type 1 is defined to transform the real numbers \(\boldsymbol{y}=(y_i)_{i=0}^N\) into \(\boldsymbol{Y}=(Y_i)_{i=0}^N\) such that
This operation can be evaluated in \(\mathcal{O}(N \log_2 N)\) floating point operations, using the Fast Fourier Transform (FFT). Vectorized:
\[
\boldsymbol{Y} = DCT^1(\boldsymbol{y})
\]
The DCT is found in scipy and we will now use it to compute a fast Chebyshev transform.
Fast Chebyshev transform
We have the \(DCT^1\) for any \(\boldsymbol{Y}\) and \(\boldsymbol{y}\)\[ \small
Y_i = y_0 + (-1)^{i}y_N + 2\sum_{j=1}^{N-1}y_j \cos(ij\pi / N), \quad i=0,1,\ldots, N
\]
We want to compute the following using the fast \(DCT^1\)\[ \small
u_N(x_i) = \hat{u}_0 + (-1)^{i}\hat{u}_N + \sum_{j=1}^{N-1} \hat{u}_j \cos(j i \pi /N), \quad i=0,1,\ldots, N \tag{1}
\]
Rearrange (1) my multiplying by 2: \[ \small
2u_N(x_i)-\hat{u}_0-(-1)^{i}\hat{u}_N = \overbrace{\hat{u}_0 + (-1)^{i}\hat{u}_N + 2\sum_{j=1}^{N-1}\hat{u}_j \cos(ij\pi / N)}^{DCT^1(\boldsymbol{\hat{u}})_i}
\]